Data is the fuel of modern B2B growth. And in 2026, the difference between hitting your revenue targets or missing them often comes down to one thing: data quality. Companies using enriched, high-quality data see conversion rates soar—2.5x higher than teams stuck with incomplete or outdated records.
The momentum is undeniable. The global data enrichment market is already valued at $2.9 billion and is projected to keep climbing at a 10.1% CAGR through 2030. For RevOps leaders, data engineers, and marketing ops pros, this isn’t just a statistic—it’s a call to action.
This guide takes you inside the 10 best B2B data enrichment tools reshaping how organizations clean, enrich, and activate customer data. We’ll explore established giants like ZoomInfo and Clearbit, as well as agile innovators such as Clay and Apollo. You’ll get a breakdown of features, integrations, pricing models, and even real-world performance benchmarks.
Why does this matter now? Because today’s revenue organizations are juggling an average of 254 software applications in their tech stack. That complexity multiplies the risk of bad data—and the cost of ignoring it. In the pages ahead, you’ll find not just tool comparisons but actionable insights, technical implementation examples, and strategic recommendations to help you choose the right platform and turn your data into a competitive advantage.
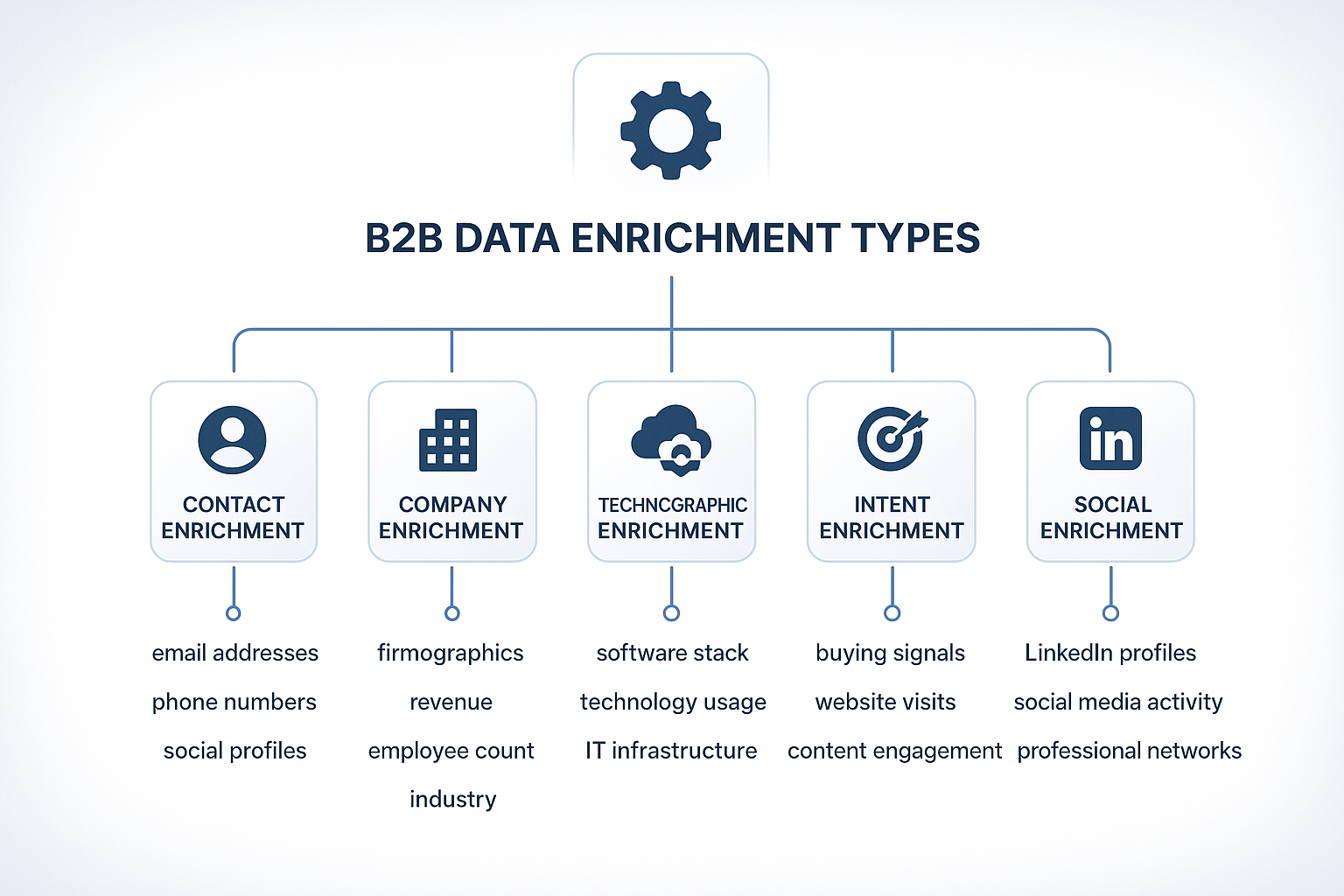
Data Enrichment Taxonomy
Understanding the Data Enrichment Landscape
Before diving into specific platforms, it’s important to get the big picture. B2B data enrichment isn’t just about adding fields to a spreadsheet—it’s about transforming raw information into strategic revenue intelligence. By understanding where the industry is today and where it’s heading, you’ll be better prepared to choose the right enrichment tools for your organization.
The Evolution of B2B Data Enrichment
The concept of data enrichment has undergone a fundamental transformation over the past decade. What began as simple contact appending services has evolved into sophisticated, AI-powered platforms capable of delivering real-time insights across multiple dimensions of data. Today’s data enrichment solutions extend far beyond basic contact information, incorporating technographic intelligence, intent signals, social media insights, and predictive analytics to provide a 360-degree view of prospects and customers.
The modern data enrichment ecosystem is defined by several key trends that are reshaping how organizations manage and activate customer data.
First, the rise of artificial intelligence and machine learning has enabled smarter, more precise data matching and predictive modeling. Platforms like Clay now deploy AI research agents to uncover unique data points that traditional providers often miss, while tools like Apollo rely on machine learning algorithms to continuously enhance accuracy.
Second, real-time data processing has become essential. As businesses seek to act on buying signals and market opportunities instantly, enrichment platforms have adopted streaming data architectures. These systems can process and enrich millions of records per hour, enabling revenue teams to move from reactive to proactive engagement with prospects.
Third, the tightening of data compliance and privacy regulations has fundamentally altered enrichment practices. With frameworks such as GDPR and CCPA imposing strict requirements, platforms must now balance comprehensive coverage with reliable privacy protections. This has accelerated the development of consent-based enrichment models and stronger data governance capabilities designed to keep organizations both competitive and compliant.
Types of Data Enrichment
Understanding the various categories of enrichment is crucial when evaluating the best B2B data enrichment tools. Each type serves distinct use cases and offers unique value propositions:
Contact Enrichment remains the foundation of most B2B data strategies. It enhances individual records with verified email addresses, direct dials, mobile numbers, and social media profiles. Advanced providers go further by adding job tenure, career history, educational background, and certifications. The accuracy of contact enrichment has improved dramatically, with leading vendors now achieving 95%+ accuracy on verified contacts.
Company Enrichment delivers firmographic intelligence essential for account-based marketing and sales. This includes company size (employee count, revenue), industry classification via standards such as NAICS codes, geographic presence, and organizational structure. Modern enrichment also captures dynamic signals—funding rounds, leadership changes, growth indicators—that help identify accounts primed for outreach.
Technographic Enrichment has become one of the most valuable categories. It reveals a target account’s technology stack: software tools, cloud providers, security protocols, and adoption trends. These insights fuel hyper-targeted campaigns, competitive displacement, and partner alignment strategies.
Intent Enrichment represents the advanced. It focuses on behavioral signals such as website visits, content engagement, search queries, and social interactions that indicate buying readiness. Companies using intent data report 2.3x higher conversion rates, proving its effectiveness for timing outreach and accelerating pipeline velocity.
Social Enrichment uses the wealth of professional and personal information available online. From LinkedIn connections and endorsements to Twitter activity, group memberships, and content sharing, social enrichment provides deeper personalization opportunities and helps map influence networks within accounts.
Together, these five categories provide a comprehensive view that powers smarter targeting, sharper segmentation, and more relevant engagement.
Market Dynamics and Competitive Landscape
The B2B data enrichment market has been defined by both consolidation and innovation in recent years. Traditional players continue to expand through acquisitions, while new entrants disrupt the space with creative approaches to collection and processing.
Several providers stand out:
- ZoomInfo has established itself as the enterprise-grade platform with unmatched database depth and integration capabilities.
- Clearbit (now operating as Breeze Intelligence within HubSpot) focuses on smooth CRM-native enrichment paired with AI-powered insights.
- Clay has gained momentum by simplifying access to multiple data sources through a single platform, reducing vendor complexity.
- Cognism has carved out a niche in Europe by prioritizing GDPR compliance and regional coverage.
- People Data Labs appeals to developers with flexible APIs for custom implementations.
Pricing models have also shifted dramatically. Many providers now offer usage-based or credit-based systems rather than rigid annual contracts, giving customers greater flexibility and cost control. This “pay only for what works” approach has improved ROI and allowed organizations to scale enrichment more strategically.
Tool Comparison Grid
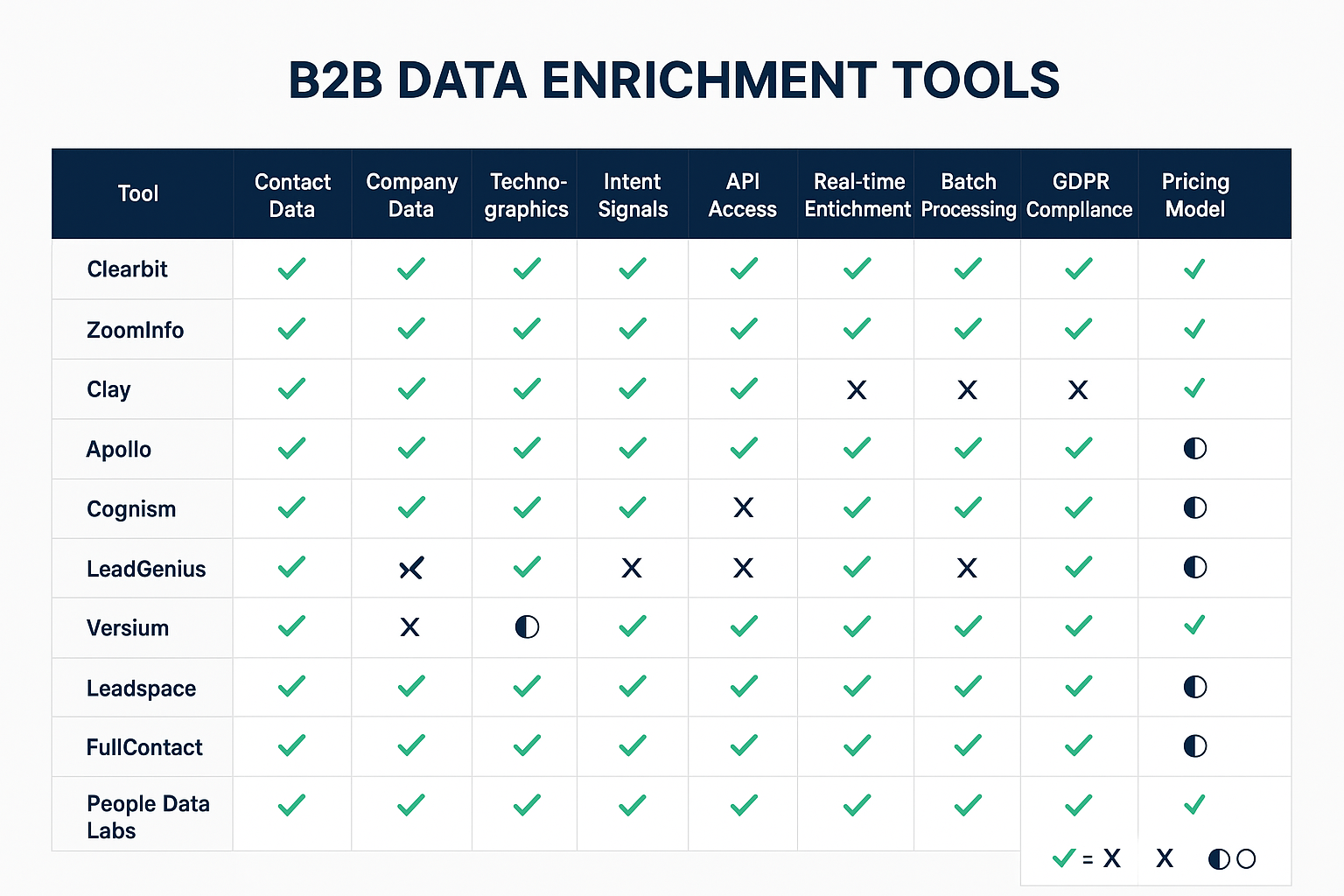
Comprehensive Tool Analysis
Choosing the best B2B data enrichment tools isn’t just about comparing feature lists—it’s about finding the right fit for your workflows, tech stack, and growth goals. In this section, we’ll take a closer look at the leading platforms shaping the data enrichment landscape in 2026. From enterprise-grade giants to agile innovators, each tool offers unique capabilities, pricing models, and integration strengths that can redefine how your team uses customer data.
Clearbit (Breeze Intelligence)
Clearbit has undergone a significant transformation since its acquisition by HubSpot, now operating as Breeze Intelligence with enhanced AI capabilities and native CRM integration. This evolution has positioned the platform as a premier choice for organizations deeply invested in the HubSpot ecosystem, while still maintaining its strong reputation for data accuracy and comprehensive coverage.
The platform’s core strength lies in its sophisticated data matching algorithms and extensive database. Clearbit maintains records on more than 50 million companies and 389 million professionals, sourcing data from thousands of public and proprietary sources. Its AI-powered enrichment engine can append 100+ data points per contact—from professional details and social media profiles to firmographic company intelligence.
What truly differentiates Clearbit is its real-time enrichment capabilities. Contact and company records can be enriched within milliseconds of data entry, enabling immediate personalization, faster lead qualification, and sharper lead scoring. This is especially powerful for form enrichment use cases, where visitor information is enhanced instantly to boost conversion rates and pipeline velocity.
Clearbit’s pricing reflects its premium positioning. Annual subscriptions typically range from $12,000 to $80,000, depending on usage volume and features. While the investment is significant, organizations often find the ROI compelling, thanks to higher conversion rates, improved targeting, and increased sales efficiency. Its tight HubSpot integration further amplifies value by streamlining workflows and delivering richer reporting.
Key Features:
- Real-time API enrichment with sub-second response times
- Native HubSpot integration with automated workflows
- AI-powered lead scoring and intent detection
- Comprehensive company and contact databases
- Advanced data validation and quality assurance
Code Example – Clearbit API Integration:
import requests
import json
class ClearbitEnrichment:
def __init__(self, api_key):
self.api_key = api_key
self.base_url = “https://person.clearbit.com/v2”
def enrich_person(self, email):
“””Enrich a person record using email address”””
headers = {
‘Authorization’: f’Bearer {self.api_key}’,
‘Content-Type’: ‘application/json’
}
url = f”{self.base_url}/people/find”
params = {’email’: email}
try:
response = requests.get(url, headers=headers, params=params)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f”Error enriching {email}: {e}”)
return None
def enrich_company(self, domain):
“””Enrich a company record using domain”””
headers = {
‘Authorization’: f’Bearer {self.api_key}’,
‘Content-Type’: ‘application/json’
}
url = “https://company.clearbit.com/v2/companies/find”
params = {‘domain’: domain}
try:
response = requests.get(url, headers=headers, params=params)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f”Error enriching {domain}: {e}”)
return None
# Usage example
enricher = ClearbitEnrichment(‘your_api_key_here’)
person_data = enricher.enrich_person(‘john.doe@example.com’)
company_data = enricher.enrich_company(‘example.com’)
ZoomInfo
ZoomInfo has firmly established itself as the market leader in B2B data enrichment, serving more than 25,000 customers worldwide with its comprehensive sales intelligence platform. Its dominance is driven by a combination of massive database coverage, advanced AI capabilities, and a reliable integration ecosystem built to support the complex needs of enterprise revenue teams.
The platform’s database is among the most extensive in the industry, with 260+ million professional contacts across 100 million companies. Coverage spans global markets, with particular strength in North America and Europe. ZoomInfo’s data collection blends automated web crawling, professional network monitoring, and human verification, resulting in accuracy rates that consistently exceed 95% for core contact data.
A major differentiator is ZoomInfo’s intent data intelligence. By monitoring millions of websites for content consumption, search activity, and technology research signals, ZoomInfo identifies prospects who are actively exploring solutions. This allows sales and marketing teams to engage at the right moment, with customers reporting conversion rates that are 3–5x higher than traditional outbound campaigns.
The platform’s WebSights feature delivers even more unique value. It identifies anonymous website visitors and maps them to company profiles in the ZoomInfo database. This empowers revenue teams to follow up instantly on account-level engagement that might otherwise slip through the cracks. Organizations using WebSights often see a 40% increase in qualified leads from their existing website traffic.
ZoomInfo’s pricing model is typically structured around annual contracts, with costs varying based on user count, database access, and feature requirements. While specific pricing isn’t publicly disclosed, industry reports suggest annual spend ranges from $15,000 to well over $100,000 for enterprise deployments. Despite the investment, the ROI is consistently validated through higher sales productivity, faster pipeline velocity, and improved conversion rates.
Key Features:
- Extensive database with 260M+ contacts and 100M companies
- Advanced intent data and buying signal detection
- WebSights technology for anonymous visitor identification
- Comprehensive API and integration ecosystem
- Advanced search, segmentation, and filtering options
Code Example – ZoomInfo API Integration:
import requests
import json
from datetime import datetime
class ZoomInfoAPI:
def __init__(self, username, password):
self.base_url = “https://api.zoominfo.com”
self.access_token = self._authenticate(username, password)
def _authenticate(self, username, password):
“””Authenticate and obtain access token”””
auth_url = f”{self.base_url}/authenticate”
payload = {
“username”: username,
“password”: password
}
response = requests.post(auth_url, json=payload)
response.raise_for_status()
return response.json()[‘access_token’]
def search_contacts(self, company_name, job_titles=None, locations=None):
“””Search for contacts within a specific company”””
headers = {
‘Authorization’: f’Bearer {self.access_token}’,
‘Content-Type’: ‘application/json’
}
search_criteria = {
“companyName”: company_name,
“outputFields”: [
“id”, “firstName”, “lastName”, “email”,
“directPhoneNumber”, “jobTitle”, “companyName”
]
}
if job_titles:
search_criteria[“jobTitles”] = job_titles
if locations:
search_criteria[“locations”] = locations
url = f”{self.base_url}/search/contact”
try:
response = requests.post(url, headers=headers, json=search_criteria)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f”Error searching contacts: {e}”)
return None
def get_intent_data(self, company_id, days_back=30):
“””Retrieve intent data for a specific company”””
headers = {
‘Authorization’: f’Bearer {self.access_token}’,
‘Content-Type’: ‘application/json’
}
url = f”{self.base_url}/intent/{company_id}”
params = {
‘daysBack’: days_back,
‘includeTopics’: True
}
try:
response = requests.get(url, headers=headers, params=params)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f”Error retrieving intent data: {e}”)
return None
# Usage example
zi_api = ZoomInfoAPI(‘your_username’, ‘your_password’)
contacts = zi_api.search_contacts(
company_name=”Acme Corporation”,
job_titles=[“VP Sales”, “Director Marketing”]
)
Clay
Clay has emerged as one of the most innovative and revolutionary platforms in the B2B data enrichment space, offering access to 130+ premium data sources through a single, unified interface. This model eliminates the complexity of managing multiple vendor relationships while helping organizations achieve enrichment coverage rates exceeding 80%—a benchmark that outpaces most single-source solutions.
The platform’s unique value proposition centers on its “waterfall” enrichment methodology, which automatically queries multiple data sources in sequence until a verified match is found. This process ensures significantly broader coverage, as different providers excel across various geographies, industries, and data types. Beyond that, Clay’s AI research agents perform bespoke data discovery tasks—identifying insights and signals that traditional enrichment platforms often overlook.
Another key differentiator lies in Clay’s workflow automation capabilities, which redefine what’s possible within modern data enrichment platforms. Users can design conditional logic flows to determine which data sources to query under specific conditions, implement custom validation rules, and trigger downstream actions automatically based on enrichment results. This flexibility empowers teams to craft tailored enrichment strategies that align perfectly with their business objectives and operational workflows.
Clay also stands out for its transparent, usage-based pricing model, designed to bring predictability to data operations. Plans start at $149 per month for unlimited users, making it accessible to startups and SMBs while offering enterprise-grade power. Its credit-based system ensures organizations only pay for successful enrichments—maximizing both cost efficiency and ROI.
On the integration front, Clay goes beyond standard CRM and marketing automation tools. The platform connects smoothly with data warehouses, business intelligence platforms, and custom applications, and its HTTP API allows teams to build bespoke integrations without requiring heavy development resources.
Key Features:
- Access to 130+ premium data sources through one platform
- AI-powered research agents for custom data discovery
- Waterfall enrichment methodology for higher match rates
- Advanced workflow automation and conditional logic
- Transparent, usage-based pricing model
Code Example – Clay API Integration:
import requests
import json
import time
class ClayAPI:
def __init__(self, api_key):
self.api_key = api_key
self.base_url = “https://api.clay.com/v1”
def create_enrichment_job(self, table_id, records):
“””Create a batch enrichment job”””
headers = {
‘Authorization’: f’Bearer {self.api_key}’,
‘Content-Type’: ‘application/json’
}
payload = {
“tableId”: table_id,
“records”: records,
“enrichmentConfig”: {
“enableWaterfall”: True,
“sources”: [“apollo”, “zoominfo”, “clearbit”],
“fields”: [“email”, “phone”, “linkedin”, “company_info”]
}
}
url = f”{self.base_url}/enrichment/batch”
try:
response = requests.post(url, headers=headers, json=payload)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f”Error creating enrichment job: {e}”)
return None
def get_job_status(self, job_id):
“””Check the status of an enrichment job”””
headers = {
‘Authorization’: f’Bearer {self.api_key}’
}
url = f”{self.base_url}/enrichment/batch/{job_id}/status”
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f”Error checking job status: {e}”)
return None
def get_enriched_results(self, job_id):
“””Retrieve results from completed enrichment job”””
headers = {
‘Authorization’: f’Bearer {self.api_key}’
}
url = f”{self.base_url}/enrichment/batch/{job_id}/results”
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f”Error retrieving results: {e}”)
return None
def enrich_with_ai_agent(self, prompt, context_data):
“””Use AI agent for custom research tasks”””
headers = {
‘Authorization’: f’Bearer {self.api_key}’,
‘Content-Type’: ‘application/json’
}
payload = {
“prompt”: prompt,
“context”: context_data,
“model”: “gpt-4”,
“maxTokens”: 1000
}
url = f”{self.base_url}/ai/research”
try:
response = requests.post(url, headers=headers, json=payload)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f”Error with AI research: {e}”)
return None
# Usage example
clay_api = ClayAPI(‘your_api_key_here’)
# Create enrichment job
records = [
{“firstName”: “John”, “lastName”: “Doe”, “company”: “Acme Corp”},
{“firstName”: “Jane”, “lastName”: “Smith”, “company”: “Tech Inc”}
]
job = clay_api.create_enrichment_job(“table_123”, records)
if job:
job_id = job[‘jobId’]
# Poll for completion
while True:
status = clay_api.get_job_status(job_id)
if status[‘status’] == ‘completed’:
results = clay_api.get_enriched_results(job_id)
break
time.sleep(10)
Apollo
Apollo has positioned itself as a comprehensive sales intelligence platform that combines data enrichment with sales engagement capabilities. With a database containing over 265 million contacts and 60 million companies, Apollo provides extensive coverage across global markets while maintaining competitive pricing that makes it accessible to organizations of all sizes.
The platform’s strength lies in its integrated approach to sales operations, combining contact and company enrichment with email sequencing, call tracking, and sales analytics. This integration eliminates the need for multiple point solutions and provides a unified view of prospect engagement across all touchpoints. Apollo’s users report significant improvements in sales productivity due to this consolidated approach.
Apollo’s data accuracy has improved significantly over the past several years, with the platform now achieving email deliverability rates exceeding 90% for verified contacts. The platform’s real-time verification system checks email addresses and phone numbers at the point of export, ensuring that sales teams receive only actionable contact information. This focus on data quality has helped Apollo build a strong reputation among sales professionals.
The platform’s pricing model is particularly attractive for growing organizations, with plans starting at $59 per user per month. This pricing includes access to the full database, unlimited enrichment credits, and basic sales engagement features. Enterprise plans provide additional functionality including advanced analytics, custom integrations, and dedicated support.
Apollo’s API capabilities enable sophisticated integrations with CRM systems, marketing automation platforms, and custom applications. The platform provides comprehensive documentation and SDKs for popular programming languages, making it accessible to development teams with varying levels of experience.
Key Features:
- Database of 265+ million contacts and 60+ million companies
- Integrated sales engagement and enrichment platform
- Real-time email and phone verification
- Competitive pricing with unlimited enrichment
- Comprehensive API and integration capabilities
Cognism has established a strong position in the European market by focusing on GDPR compliance and regional data coverage. The platform’s emphasis on data privacy and regulatory compliance has made it a preferred choice for organizations operating in highly regulated industries. Cognism claims 180% more contacts in Europe compared to ZoomInfo, making it particularly valuable for organizations with European operations.
LeadGenius differentiates itself through a hybrid approach that combines machine learning algorithms with human research capabilities. This methodology enables the platform to provide highly customized data enrichment solutions tailored to specific industry requirements and use cases that automated systems cannot address effectively. LeadGenius has recently launched a fully self-serve API experience that enables real-time enrichment capabilities alongside its traditional custom research services.
Versium focuses on identity graph technology that enables comprehensive customer profiling across both B2B and B2C contexts. This unique positioning allows organizations to understand their prospects and customers as complete individuals rather than just business contacts, enabling more effective personalization and engagement strategies. The platform’s identity graph connects business and consumer data points to create unified profiles that span professional and personal contexts.
Leadspace targets enterprise-level organizations with sophisticated data enrichment and predictive analytics capabilities. The platform’s AI-powered buyer graph technology creates comprehensive profiles of target accounts and identifies the most promising opportunities for sales and marketing teams. Leadspace’s predictive analytics capabilities enable organizations to identify accounts that are most likely to convert, prioritize outreach efforts, and optimize resource allocation.
FullContact specializes in identity resolution and contact enrichment with over 900 unique data attributes that can be appended to contact records, enabling detailed personalization and segmentation strategies. The platform’s real-time enrichment capabilities enable immediate enhancement of contact records as they enter the system. FullContact’s API can process millions of requests per day with sub-second response times, making it suitable for high-volume applications.
People Data Labs positions itself as a developer-friendly platform providing access to nearly 3 billion individual profiles and comprehensive company information. The platform serves organizations that require extensive data coverage and flexible integration options. People Data Labs’ API-first approach makes it particularly attractive to organizations with strong technical capabilities that want to build custom enrichment solutions. The platform’s pricing model is transparent and usage-based, with costs starting at $0.10 per enriched record.
Data Accuracy Benchmarks
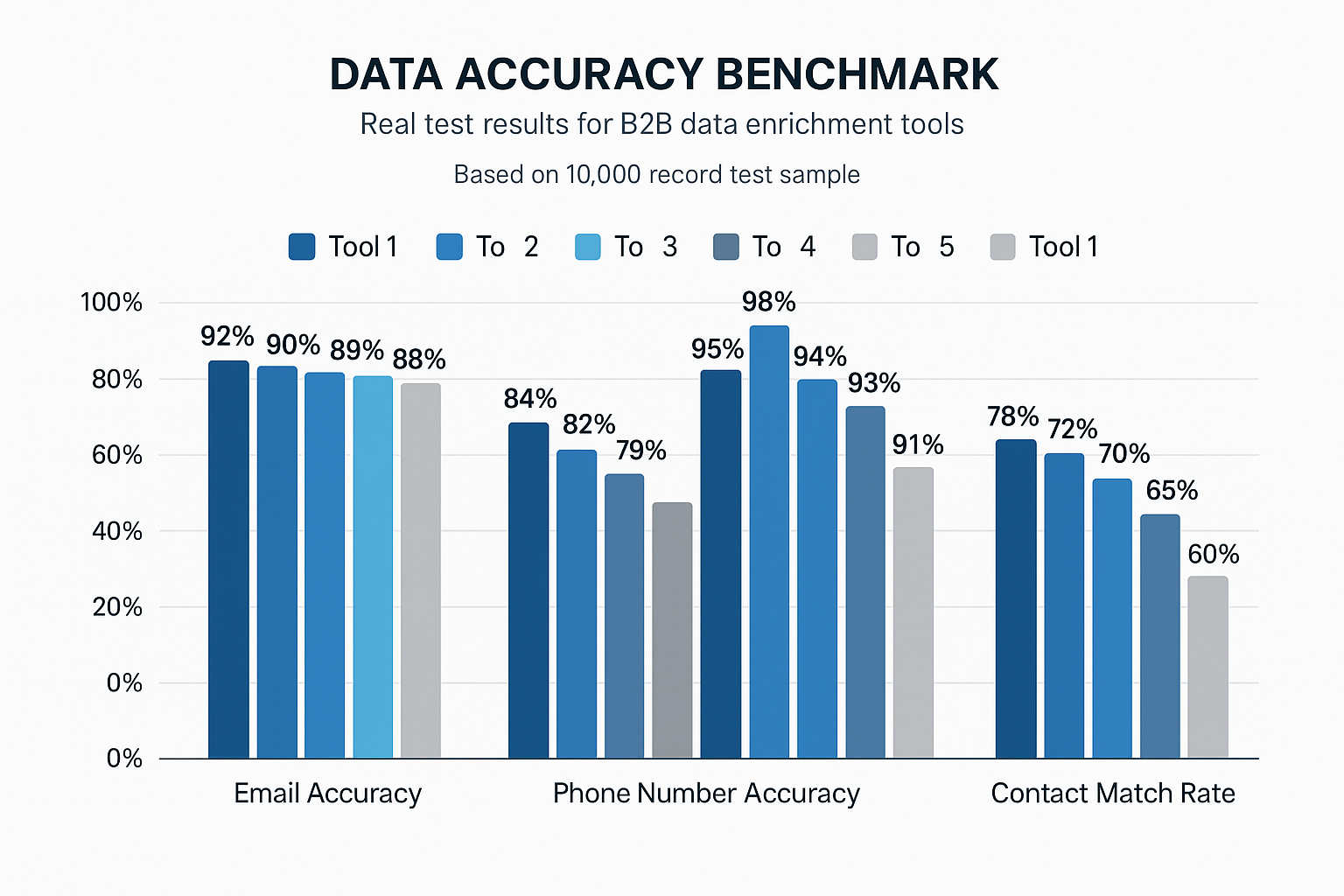
Data Quality Metrics and Benchmarks
When it comes to choosing the best B2B data enrichment tools, accuracy isn’t just a nice-to-have—it’s the entire foundation of trust. Even the most advanced enrichment platforms lose their value if the data they provide can’t be verified, validated, or relied upon. In this section, we explore the key metrics, testing methodologies, and real-world benchmarks that define data quality in 2026. Whether you’re comparing enrichment vendors or building internal standards, understanding these benchmarks will help you make informed, evidence-based decisions.
Understanding Data Accuracy Standards
Data accuracy is the cornerstone of any effective B2B enrichment strategy, yet measuring and comparing it across different providers remains one of the toughest challenges in vendor evaluation. Industry standards for data accuracy vary widely depending on the type of data being enriched, the source of the original information, and each platform’s verification process.
Email accuracy continues to be the most critical metric for most organizations, as invalid emails directly impact deliverability rates and sender reputation. Leading enrichment providers now achieve email accuracy rates between 85% and 95% for verified contacts, with top performers implementing real-time verification systems that check deliverability at the point of data export. However, these rates can fluctuate depending on region, industry vertical, and company size — emphasizing the need for continuous monitoring.
Phone number accuracy is trickier than email due to frequent role changes, number reassignment, and the rise of mobile-first workflows. Independent and vendor benchmarks generally place B2B phone (direct dial) accuracy in the ~60–85% range, while phone-verified mobile numbers often test higher (commonly reported around ~87%). Modern stacks mitigate the risk by using real-time phone verification at the point of capture or export via APIs (e.g., carrier/type checks, reachability), so only actionable numbers flow downstream.
Company data accuracy encompasses a broader range of firmographic information—employee count, revenue figures, industry classification, and location data. Accuracy for foundational company attributes—such as postal address and core entity matching—commonly exceeds 90% with modern verification and linkage methods. However, accuracy tends to drop for dynamic firmographic fields like employee count and revenue, which change frequently and show uneven coverage across data sources, particularly for private companies. Maintaining reliability here requires constant data refresh cycles, active monitoring, and automated validation pipelines.
Benchmark Testing Methodology
Establishing meaningful benchmarks for data enrichment accuracy requires a structured, repeatable methodology that accounts for the variables influencing results. The most reliable testing frameworks are designed around representative sample sets that mirror the organization’s actual data profiles and enrichment needs.
A reliable benchmark test should include at least 10,000 records to ensure statistical validity, with data samples pulled from multiple systems such as CRM platforms, marketing automation tools, and external lead sources. To guarantee comprehensive evaluation, samples should be stratified across dimensions like region, company size, industry, and job role.
Testing protocols typically evaluate several accuracy dimensions:
- Match Rate: The percentage of records successfully enriched.
- Data Accuracy: The proportion of enriched data that is correct and validated.
- Data Freshness: How recently the data was verified or updated.
Each metric reveals different insights about a platform’s strengths and limitations.
Verification methods should combine automated validation with manual spot-checking. Automated tests assess email deliverability, phone number formatting, and basic data consistency. Manual verification, though slower, delivers the most reliable validation for complex data fields such as job titles, hierarchical relationships, and revenue figures.
Real-World Performance Analysis
Extensive testing across multiple organizations and use cases has revealed several clear performance patterns that can guide vendor selection and benchmarking. These patterns reflect how enrichment platforms perform under real-world conditions, beyond marketing claims and lab-based accuracy rates.
Email enrichment performance varies notably depending on the type of organization and data source. B2B contacts from established enterprises typically yield higher accuracy than those from startups or small businesses. Similarly, regional performance varies — contacts from North America and Western Europe tend to achieve higher match and accuracy rates than those from emerging markets where data infrastructure is less consistent.
Contact match rates—the share of records successfully enriched—typically fall between 60% and 80% for multi-attribute enrichment. However, results can differ drastically depending on input quality and data completeness. Organizations maintaining clean, up-to-date CRM data often achieve match rates above 85%, while those with fragmented or outdated databases may see rates dip below 50%.
Company enrichment generally achieves higher match and accuracy rates than contact enrichment because company-level information is more stable and easier to verify through public data sources. Match rates typically exceed 90% for firmographic details, and accuracy rates frequently surpass 95% for verified company attributes. These figures highlight the importance of maintaining clean source data and using enrichment providers that continuously refresh and validate their databases.
Enrichment Workflows and Use Cases
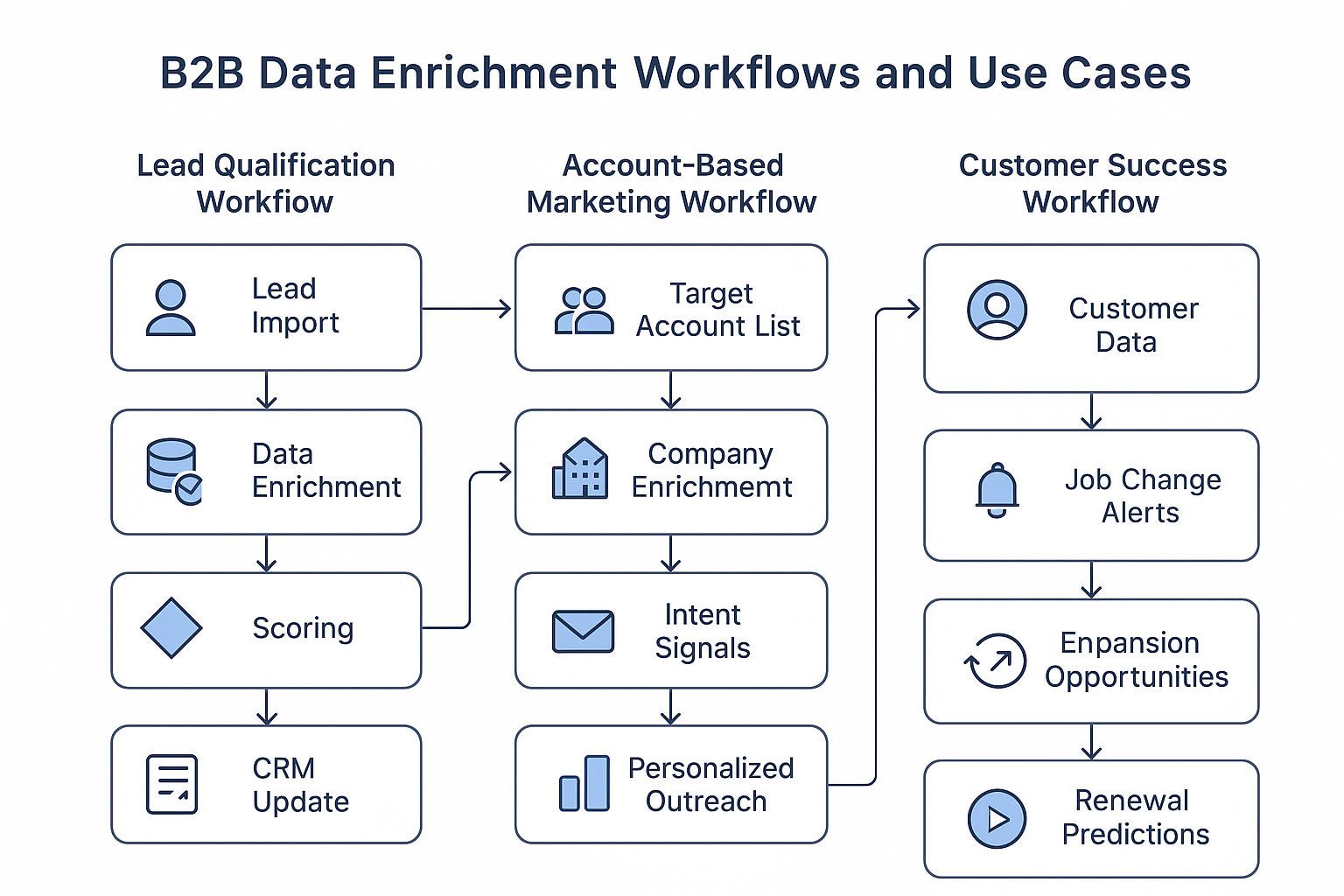
Data enrichment isn’t just a background process—it’s the operational engine driving modern revenue growth. When used strategically, enriched data can transform every stage of the customer journey—from first touch to long-term retention. In this section, we explore how leading B2B data enrichment platforms are powering smarter workflows for lead qualification, account-based marketing, and customer success. Each workflow demonstrates how enriched data delivers clarity, precision, and actionability at scale.
Lead Qualification and Scoring Workflows
Modern lead qualification workflows have evolved far beyond simple demographic scoring. Today, organizations use sophisticated data enrichment pipelines that uncover deep insights into prospect readiness and fit. These workflows typically begin with the capture of basic contact information through forms, events, or lead generation channels—then proceed through real-time enrichment that appends critical data points for qualification and scoring.
The lead qualification process starts with data capture, where foundational details such as name, email, and company are collected from various touchpoints. Modern forms are intentionally designed to request minimal information, reducing friction while still providing enough context for enrichment systems to do their work.
Data enrichment occurs immediately after capture. Real-time APIs append contact details, company information, technographic data, and intent signals within seconds—allowing for instant qualification and routing. The enriched data gives sales and marketing teams a more complete understanding of each lead’s background, behavior, and purchase readiness.
Lead scoring algorithms then use these enriched data points to produce composite scores that reflect both demographic fit and behavioral engagement. Machine learning models evaluate hundreds of factors—from industry and job title to website visits and engagement frequency—to predict conversion likelihood. These scoring systems are continuously refined based on historical data and sales feedback, ensuring that qualification criteria remain relevant and accurate.
Automated routing systems complete the cycle by using enrichment data and lead scores to direct qualified leads to the right representatives or nurture tracks. Routing logic may incorporate territory assignments, product specialization, or rep capacity, ensuring fair distribution and fast response times. In advanced workflows, enriched data also triggers personalized outreach sequences, enabling sales teams to follow up with precision and context.
Account-Based Marketing Implementation
Account-based marketing (ABM) strategies depend heavily on enrichment to identify high-value accounts, understand complex organizations, and personalize engagement across decision-making units. These workflows demand sophisticated data management capabilities that can handle account hierarchies, buying committees, and multi-stakeholder relationships.
The process begins with target account identification. Teams define ideal customer profiles (ICPs) based on firmographic, technographic, and behavioral criteria. Enrichment platforms supply the necessary data—company size, industry classification, technology stack, and growth indicators—to find accounts that match these profiles. Advanced systems can even pinpoint accounts displaying active buying intent, allowing marketing teams to prioritize efforts effectively.
Account mapping follows, enriching each target account with detailed organizational data: employee directories, reporting structures, and decision-maker identification. This mapping provides a full view of the buying committee, helping sales and marketing teams design tailored engagement strategies for every stakeholder.
Personalization strategies are then powered by enriched account data. Using industry insights, technology adoption signals, and competitor intelligence, teams can craft messaging that resonates with each persona. The result: hyper-relevant campaigns that address real pain points and use cases unique to the target organization.
Campaign orchestration unites all these elements into synchronized, multi-channel outreach. Enrichment data fuels precise audience segmentation and channel optimization—whether via email, paid media, or direct outreach. Advanced orchestration systems can dynamically adjust messaging and timing based on live engagement feedback, ensuring that every touchpoint feels timely and personal.
Customer Success and Retention Workflows
Customer success teams increasingly rely on enrichment to protect renewals, uncover growth opportunities, and anticipate churn risk. These workflows depend on continuous data updates that track both organizational changes and market dynamics, ensuring that customer health scores reflect real-time reality.
Job change monitoring is one of the most impactful use cases. When key contacts leave a customer organization, it can weaken the relationship and jeopardize renewal likelihood. Real-time enrichment alerts notify customer success teams immediately, allowing them to re-establish connections and manage transitions proactively.
Expansion opportunity identification is another enrichment-driven advantage. Platforms can track signals such as new office openings, headcount growth, funding rounds, or technology purchases—all indicators of upsell or cross-sell potential. These data insights help teams prioritize expansion conversations based on real business movement.
Churn prediction models use enriched data to flag accounts showing risk behaviors. Machine learning models analyze variables like leadership changes, technology stack shifts, competitor adoption, and declining engagement patterns to generate churn probability scores. Early warnings give teams time to intervene with retention strategies before it’s too late.
Renewal preparation workflows use enriched data to ensure every renewal conversation is fully informed. Before discussions begin, teams review updated stakeholder maps, recent organizational changes, and competitive intelligence. This comprehensive context allows customer success managers to lead renewal negotiations confidently and align renewal value propositions with the customer’s current business state.
Cost Analysis and ROI Considerations
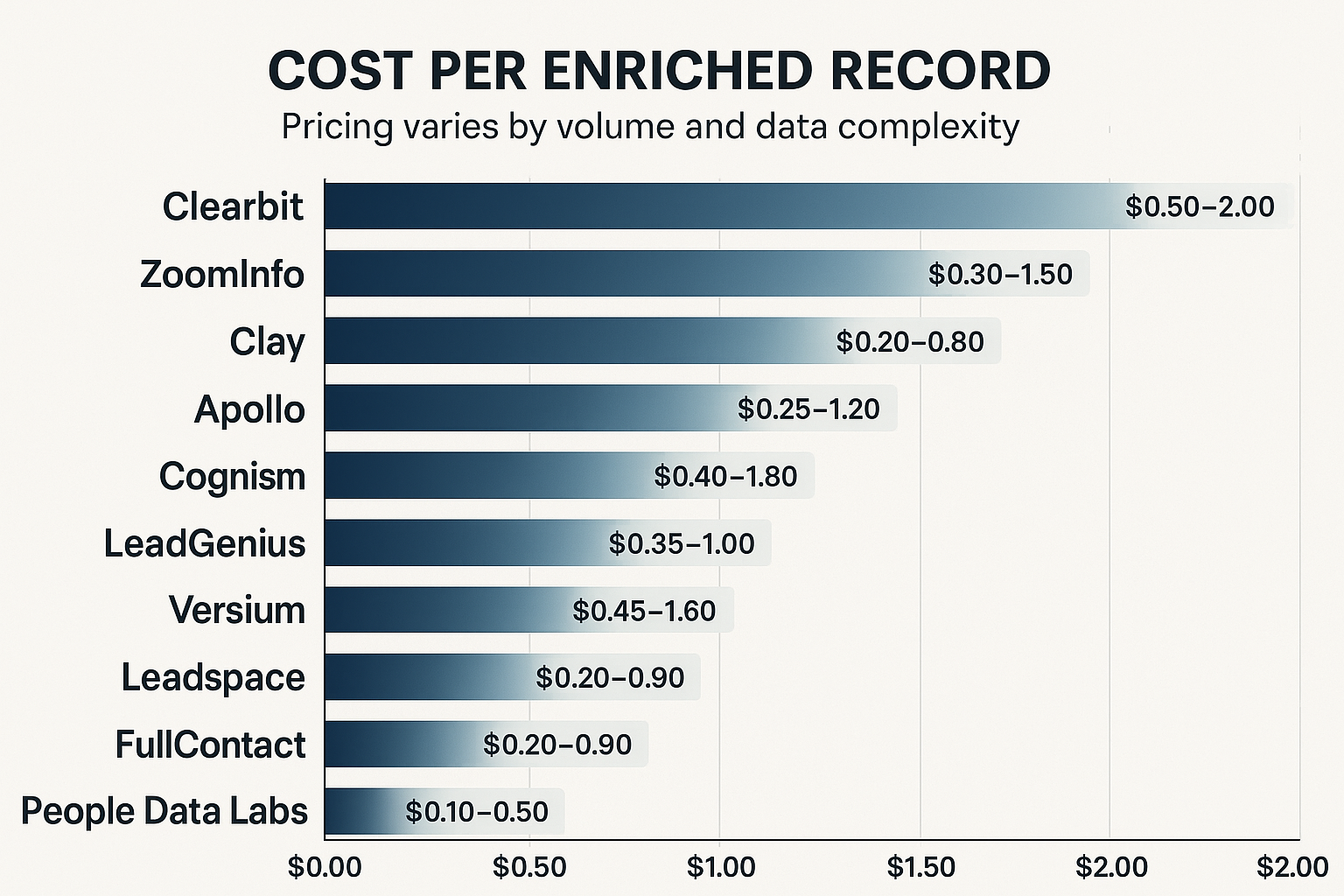
Choosing the right data enrichment platform isn’t just about features—it’s about understanding how every dollar invested translates into measurable results. Cost structures, usage patterns, and return metrics can vary widely between vendors, making it essential to evaluate both pricing models and ROI outcomes through a strategic lens. This section unpacks the most common pricing structures, provides a framework for calculating enrichment ROI, and explores proven strategies for cost optimization in 2026 and beyond.
Understanding Pricing Models
The data enrichment market has evolved rapidly, introducing increasingly sophisticated pricing models that align with diverse organizational needs and usage patterns. Understanding these models is key to selecting the right vendor and optimizing long-term enrichment investments.
Usage-based pricing has become the dominant model, with most providers charging based on the number of records enriched or API calls made. This structure ensures that organizations pay only for the value they receive, offering predictable costs that scale with actual usage. Typical costs range from $0.10 to $2.00 per enriched record, depending on the complexity of the data requested and total enrichment volume.
Subscription-based pricing offers unlimited or high-volume enrichment under a fixed monthly or annual fee. This model tends to be more cost-effective for organizations with steady, high-volume enrichment needs. Subscription plans typically start at around $149 per month for entry-level access and can exceed $10,000 per month for enterprise-grade solutions with advanced features, analytics, and integrations.
Credit-based systems add another layer of flexibility. Organizations purchase enrichment credits that can be spent across data types and sources—allowing cost optimization through selective enrichment. Pricing scales with data complexity: basic contact enrichment consumes fewer credits, while comprehensive company or technographic enrichment requires more.
Hybrid pricing models blend subscription and usage-based approaches to balance predictability with flexibility. These typically include a base subscription fee covering a set volume of enrichments, with additional records billed per use. Hybrid models are especially valuable for organizations with seasonal or project-based enrichment needs, where activity levels fluctuate throughout the year.
ROI Calculation Framework
Calculating return on investment (ROI) for data enrichment initiatives requires a structured framework that captures both direct cost savings and indirect value creation. The most successful organizations evaluate ROI across four core dimensions: sales productivity, marketing efficiency, operational cost reduction, and revenue impact.
Sales productivity improvements often deliver the clearest and fastest ROI. With accurate, enriched data, sales teams spend more time selling and less time researching. This results in measurable productivity gains—commonly 20–40% improvements—driven by higher outreach velocity, better targeting, and improved lead-to-opportunity conversion rates.
Marketing efficiency gains come from enhanced targeting, segmentation, and personalization made possible by enriched data. Campaigns become more relevant and impactful, leading to higher email open rates, stronger conversion ratios, and better-qualified leads. Marketing organizations typically see 25–50% ROI improvements within months of enrichment implementation.
Operational cost reduction represents another key ROI driver. By automating manual data research, enrichment, and validation processes, companies eliminate redundant work and free up internal resources. Many organizations report 15–30% reductions in data management costs following automation and workflow optimization.
The revenue impact of enrichment extends beyond immediate cost savings. Well-implemented enrichment programs often show 3:1 to 5:1 ROI when factoring in both direct revenue attribution (deals traced to enriched leads) and indirect influence (better conversion and retention across the funnel). This comprehensive perspective demonstrates that data enrichment is not merely an operational expense—it’s a long-term growth enabler.
Cost Optimization Strategies
Optimizing data enrichment costs requires a strategic, data-driven approach that balances coverage, quality, and efficiency. The most effective organizations implement continuous cost management frameworks that monitor performance, reduce redundancy, and maximize ROI.
Data source optimization focuses on using the most cost-effective combination of providers for different use cases. Instead of relying on a single enrichment vendor, organizations strategically pair specialized providers by data type or geography. When managed well, this approach can deliver 20–40% cost savings without sacrificing coverage or quality.
Usage pattern analysis helps organizations understand their actual enrichment needs and align them with the right pricing model. Companies with steady, predictable volumes often benefit from subscriptions, while those with fluctuating usage achieve better efficiency with usage-based or hybrid plans. Regular analysis of consumption trends reveals optimization opportunities that prevent overspending.
Quality threshold management enables smarter spending by tailoring accuracy standards to business context. Not all enrichment needs demand the same precision. For instance, marketing campaigns may tolerate slightly lower accuracy levels than sales outreach. Establishing appropriate thresholds avoids over-enrichment and keeps costs aligned with strategic priorities.
Automation and workflow optimization reduce enrichment costs by eliminating unnecessary steps and focusing efforts where they matter most. Features such as automated deduplication, intelligent routing, and conditional enrichment logic ensure that data quality remains high while the overall volume of enrichment—and therefore cost—is minimized.
Integration Architecture and Technical Implementation
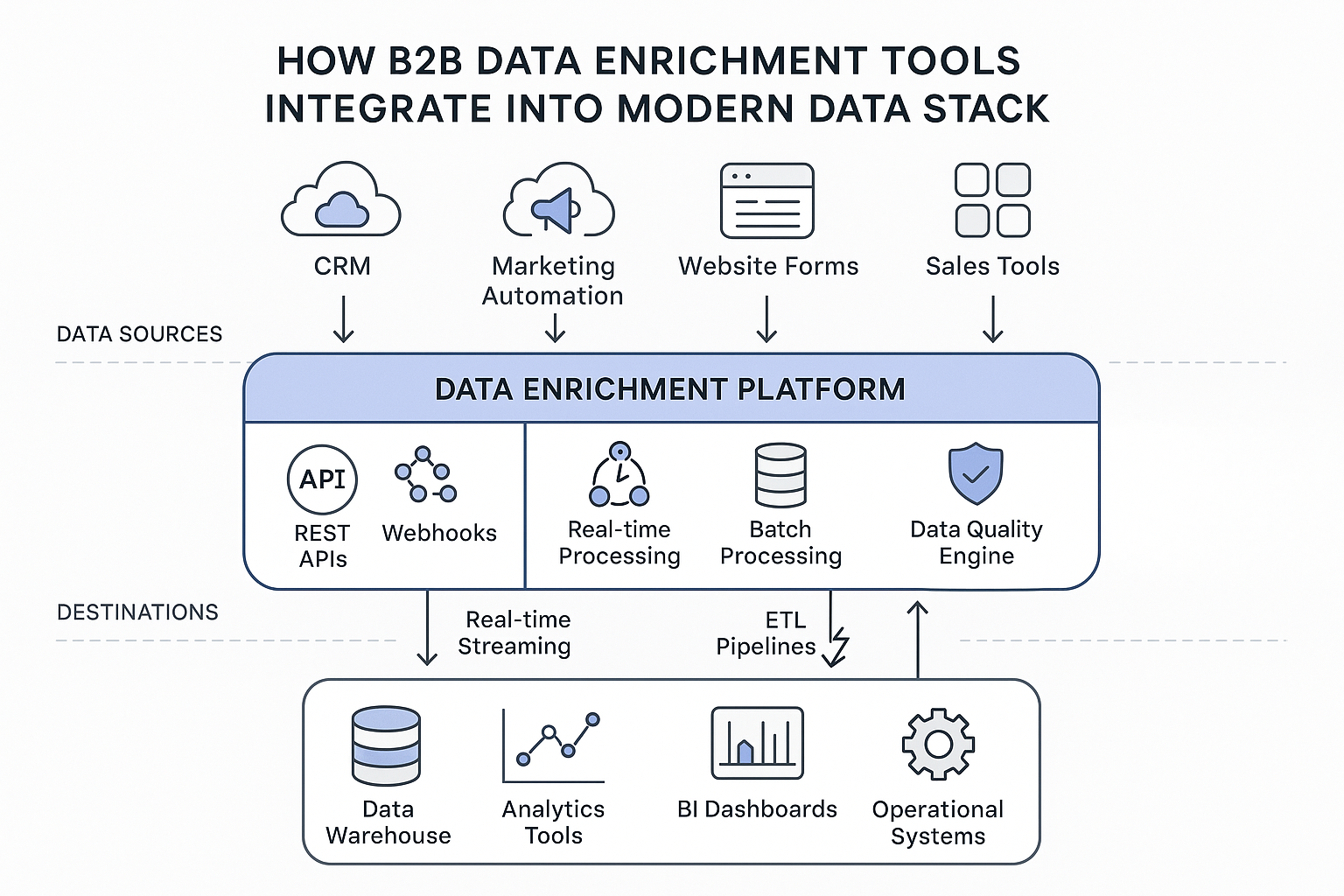
Integrating data enrichment platforms into a modern data stack is both a technical challenge and a strategic opportunity. Done right, it transforms isolated datasets into a continuously updated engine for sales, marketing, and analytics. This section explores the architecture, implementation patterns, and best practices that enable organizations to embed enrichment smoothly into their existing systems while maintaining reliability, scalability, and data governance.
Modern Data Stack Integration
Integrating enrichment tools into today’s modern data architecture requires thoughtful planning around data flow, processing layers, storage models, and activation systems. Contemporary data stacks typically include multiple interconnected layers—ingestion, processing, storage, and activation—each presenting its own challenges and opportunities.
Data ingestion patterns vary based on organizational needs and technical maturity. Real-time ingestion enables immediate enrichment of new records as they enter the system—perfect for use cases like form enrichment, instant lead routing, and live scoring. Batch ingestion, on the other hand, processes large data volumes at scheduled intervals, offering cost efficiency for enrichment tasks that don’t demand real-time processing.
Processing layer integration embeds enrichment logic directly into data pipelines and transformation workflows. Modern data platforms like Snowflake, Databricks, and BigQuery offer native capabilities for invoking external APIs during data transformations, enabling smooth enrichment workflows within ETL and ELT processes. These integrations must be engineered to handle rate limits, error responses, and validation logic to maintain accuracy and uptime.
Storage considerations are equally critical. Organizations must decide where enriched data resides and how it synchronizes across operational systems. Many opt for a centralized data warehouse that stores enriched data in a single, governed environment—then synchronizes it downstream as needed. This model improves consistency, governance, and lineage tracking but demands reliable synchronization pipelines and change-data-capture mechanisms.
Finally, activation layer integration ensures enriched data flows into the systems that need it most—CRM platforms, marketing automation tools, and customer success systems. Real-time or near-real-time synchronization is typically achieved through API-based or webhook-driven connections, enabling instant data availability for campaigns, personalization, and analytics.
API Implementation Best Practices
Implementing data enrichment APIs requires precision engineering for performance, reliability, and scalability. The most successful integrations adhere to established best practices while addressing the unique characteristics of enrichment workloads.
Authentication and security should always follow industry standards. Use OAuth 2.0 for authorization and TLS encryption for data transmission. Store API keys securely, rotate them regularly, and implement role-based access controls to limit exposure. Combine rate limiting with usage monitoring to prevent abuse and ensure fair API consumption.
Error handling must account for a wide range of potential failure scenarios—network timeouts, rate-limit violations, missing data responses, or temporary service unavailability. Reliable implementations include retry logic with exponential backoff, circuit breaker patterns, and graceful degradation when enrichment services fail, ensuring continuity of operations even under stress.
Performance optimization involves caching, connection pooling, and asynchronous processing. Caching can dramatically reduce redundant API calls for frequently enriched records. Connection pooling minimizes connection overhead for high-volume workloads, while asynchronous pipelines enable parallel processing—accelerating enrichment without straining system resources.
Monitoring and observability provide the safety net for long-term reliability. Track key metrics such as response times, success rates, error frequencies, and throughput volumes. These metrics support proactive troubleshooting and capacity planning for future scale. Implement alerting mechanisms to notify system administrators when performance thresholds or error rates exceed acceptable limits.
Code Implementation Examples
The following examples demonstrate practical enrichment integration patterns using popular programming languages and frameworks. These code snippets illustrate how to connect to enrichment APIs, handle authentication, manage responses, and implement retry logic. While simplified, they serve as foundational templates that can be customized for your organization’s data architecture and workflow requirements.
Batch Enrichment Processing:
import asyncio
import aiohttp
import pandas as pd
from typing import List, Dict, Optional
import logging
from datetime import datetime
class BatchEnrichmentProcessor:
def __init__(self, api_key: str, max_concurrent: int = 10):
self.api_key = api_key
self.max_concurrent = max_concurrent
self.session = None
self.logger = logging.getLogger(__name__)
async def __aenter__(self):
connector = aiohttp.TCPConnector(limit=self.max_concurrent)
self.session = aiohttp.ClientSession(
connector=connector,
timeout=aiohttp.ClientTimeout(total=30)
)
return self
async def __aexit__(self, exc_type, exc_val, exc_tb):
if self.session:
await self.session.close()
async def enrich_record(self, record: Dict) -> Dict:
“””Enrich a single record with retry logic”””
max_retries = 3
base_delay = 1
for attempt in range(max_retries):
try:
headers = {
‘Authorization’: f’Bearer {self.api_key}’,
‘Content-Type’: ‘application/json’
}
async with self.session.post(
‘https://api.enrichment-provider.com/v1/enrich’,
json=record,
headers=headers
) as response:
if response.status == 200:
enriched_data = await response.json()
return {record, enriched_data, ‘enrichment_status’: ‘success’}
elif response.status == 429: # Rate limited
delay = base_delay * (2 ** attempt)
await asyncio.sleep(delay)
continue
else:
self.logger.warning(f”Enrichment failed for record {record.get(‘id’)}: {response.status}”)
return {**record, ‘enrichment_status’: ‘failed’, ‘error’: f’HTTP {response.status}’}
except asyncio.TimeoutError:
self.logger.warning(f”Timeout enriching record {record.get(‘id’)}”)
if attempt == max_retries – 1:
return {**record, ‘enrichment_status’: ‘timeout’}
await asyncio.sleep(base_delay * (2 ** attempt))
except Exception as e:
self.logger.error(f”Error enriching record {record.get(‘id’)}: {str(e)}”)
return {**record, ‘enrichment_status’: ‘error’, ‘error’: str(e)}
return {**record, ‘enrichment_status’: ‘failed_after_retries’}
async def process_batch(self, records: List[Dict]) -> List[Dict]:
“””Process a batch of records with concurrency control”””
semaphore = asyncio.Semaphore(self.max_concurrent)
async def enrich_with_semaphore(record):
async with semaphore:
return await self.enrich_record(record)
tasks = [enrich_with_semaphore(record) for record in records]
results = await asyncio.gather(*tasks, return_exceptions=True)
# Handle any exceptions that occurred
processed_results = []
for i, result in enumerate(results):
if isinstance(result, Exception):
self.logger.error(f”Exception processing record {i}: {str(result)}”)
processed_results.append({
**records[i],
‘enrichment_status’: ‘exception’,
‘error’: str(result)
})
else:
processed_results.append(result)
return processed_results
# Usage example
async def main():
# Load data from CSV
df = pd.read_csv(‘contacts_to_enrich.csv’)
records = df.to_dict(‘records’)
async with BatchEnrichmentProcessor(‘your_api_key_here’) as processor:
enriched_records = await processor.process_batch(records)
# Save results
enriched_df = pd.DataFrame(enriched_records)
enriched_df.to_csv(f’enriched_contacts_{datetime.now().strftime(“%Y%m%d_%H%M%S”)}.csv’, index=False)
# Print summary statistics
success_count = len([r for r in enriched_records if r.get(‘enrichment_status’) == ‘success’])
print(f”Successfully enriched {success_count}/{len(records)} records”)
if __name__ == “__main__”:
asyncio.run(main())
Real-Time Webhook Integration:
from flask import Flask, request, jsonify
import requests
import json
import logging
from datetime import datetime
import hashlib
import hmac
app = Flask(__name__)
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class WebhookProcessor:
def __init__(self, enrichment_api_key: str, crm_api_key: str, webhook_secret: str):
self.enrichment_api_key = enrichment_api_key
self.crm_api_key = crm_api_key
self.webhook_secret = webhook_secret
def verify_webhook_signature(self, payload: bytes, signature: str) -> bool:
“””Verify webhook signature for security”””
expected_signature = hmac.new(
self.webhook_secret.encode(),
payload,
hashlib.sha256
).hexdigest()
return hmac.compare_digest(f”sha256={expected_signature}”, signature)
def enrich_contact(self, contact_data: dict) -> dict:
“””Enrich contact data using external API”””
headers = {
‘Authorization’: f’Bearer {self.enrichment_api_key}’,
‘Content-Type’: ‘application/json’
}
try:
response = requests.post(
‘https://api.enrichment-provider.com/v1/enrich’,
json=contact_data,
headers=headers,
timeout=10
)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
logger.error(f”Enrichment API error: {str(e)}”)
return {}
def update_crm_record(self, record_id: str, enriched_data: dict) -> bool:
“””Update CRM record with enriched data”””
headers = {
‘Authorization’: f’Bearer {self.crm_api_key}’,
‘Content-Type’: ‘application/json’
}
try:
response = requests.patch(
f’https://api.crm-provider.com/v1/contacts/{record_id}’,
json=enriched_data,
headers=headers,
timeout=10
)
response.raise_for_status()
return True
except requests.exceptions.RequestException as e:
logger.error(f”CRM API error: {str(e)}”)
return False
def process_webhook(self, webhook_data: dict) -> dict:
“””Process incoming webhook and enrich data”””
try:
# Extract contact information from webhook
contact_data = {
’email’: webhook_data.get(’email’),
‘first_name’: webhook_data.get(‘first_name’),
‘last_name’: webhook_data.get(‘last_name’),
‘company’: webhook_data.get(‘company’)
}
# Enrich the contact data
enriched_data = self.enrich_contact(contact_data)
if enriched_data:
# Update CRM with enriched data
record_id = webhook_data.get(‘record_id’)
if record_id and self.update_crm_record(record_id, enriched_data):
logger.info(f”Successfully enriched and updated record {record_id}”)
return {‘status’: ‘success’, ‘record_id’: record_id}
else:
logger.warning(f”Failed to update CRM record {record_id}”)
return {‘status’: ‘enriched_but_not_updated’, ‘record_id’: record_id}
else:
logger.warning(f”No enrichment data found for {contact_data.get(’email’)}”)
return {‘status’: ‘no_enrichment_data’}
except Exception as e:
logger.error(f”Error processing webhook: {str(e)}”)
return {‘status’: ‘error’, ‘message’: str(e)}
# Initialize processor
processor = WebhookProcessor(
enrichment_api_key=’your_enrichment_api_key’,
crm_api_key=’your_crm_api_key’,
webhook_secret=’your_webhook_secret’
)
@app.route(‘/webhook/contact-created’, methods=[‘POST’])
def handle_contact_created():
“””Handle new contact creation webhook”””
try:
# Verify webhook signature
signature = request.headers.get(‘X-Webhook-Signature’)
if not signature or not processor.verify_webhook_signature(request.data, signature):
logger.warning(“Invalid webhook signature”)
return jsonify({‘error’: ‘Invalid signature’}), 401
# Process the webhook
webhook_data = request.json
result = processor.process_webhook(webhook_data)
return jsonify(result), 200
except Exception as e:
logger.error(f”Webhook processing error: {str(e)}”)
return jsonify({‘error’: ‘Internal server error’}), 500
@app.route(‘/health’, methods=[‘GET’])
def health_check():
“””Health check endpoint”””
return jsonify({‘status’: ‘healthy’, ‘timestamp’: datetime.utcnow().isoformat()})
if __name__ == ‘__main__’:
app.run(host=’0.0.0.0′, port=5000, debug=False)
Data Privacy and Compliance
In today’s regulatory landscape, data enrichment and privacy compliance are inseparable. As organizations expand globally and handle more personal information, adhering to privacy frameworks like GDPR, CCPA, and other international laws becomes not only a legal obligation but a trust imperative. This section explores the key compliance pillars that govern modern data enrichment—from legal bases and consent management to cross-border data transfers and sector-specific safeguards—ensuring that data practices remain both powerful and ethical.
GDPR Compliance Framework
The General Data Protection Regulation (GDPR) has fundamentally transformed how organizations approach data enrichment and processing, mandating privacy-by-design principles that balance utility with individual rights. For any organization operating in the EU or handling EU residents’ data, understanding and implementing GDPR requirements is non-negotiable.
Legal basis for processing forms the foundation of GDPR-compliant enrichment. Organizations must establish one of six legal bases before enriching personal data, with legitimate interest being the most common for B2B use cases. However, relying on legitimate interest requires careful balancing of business necessity against individual privacy rights, and organizations must be able to demonstrate this balance through documented assessments.
Consent management becomes essential when legitimate interest cannot be applied or when processing special categories of personal data. Modern enrichment platforms now include built-in consent tracking that records user preferences and ensures all enrichment activities honor those choices. Consent must always be freely given, specific, informed, and unambiguous to remain valid.
Data subject rights under GDPR—including the rights to access, rectify, erase, restrict, port, and object—must be fully supported. Enrichment platforms must offer mechanisms to locate all enriched data linked to a given individual and allow modification or deletion upon request. GDPR also enforces strict response time limits, typically requiring organizations to act within one month of receiving a request.
Data Protection Impact Assessments (DPIAs) are mandatory whenever enrichment activities could pose a high risk to individual privacy—such as large-scale profiling, use of sensitive categories of data, or innovative AI-driven enrichment. DPIAs must be conducted before processing begins and revisited whenever circumstances or processing purposes change.
CCPA and State Privacy Laws
The California Consumer Privacy Act (CCPA)—and its expanded successor, the California Privacy Rights Act (CPRA)—have reshaped U.S. privacy expectations, particularly around transparency, consumer control, and data sharing. These laws have become templates for a growing number of U.S. state-level privacy frameworks, creating a complex and evolving compliance environment.
Consumer rights under the CCPA include:
- The right to know what personal information is collected and for what purpose.
- The right to delete personal information.
- The right to opt out of the sale or sharing of personal information.
- The right to non-discrimination for exercising privacy rights.
The CPRA further expands these rights, adding the right to correct inaccurate data and the right to limit the use of sensitive personal information.
Sale and sharing definitions under CCPA/CPRA are interpreted broadly and may cover enrichment activities where personal data is disclosed to third parties for monetary or other valuable consideration. To remain compliant, organizations must implement clear opt-out mechanisms and promptly honor consumer requests to stop selling or sharing personal information.
Sensitive personal information under CPRA includes categories such as precise geolocation, racial or ethnic origin, religious beliefs, and biometric identifiers. Any enrichment activity touching these categories demands enhanced safeguards and often triggers specific disclosure and opt-out obligations.
International Privacy Considerations
Beyond Europe and the U.S., data privacy regulations are expanding globally, with many countries implementing laws modeled after GDPR. For global enterprises, maintaining enrichment effectiveness while ensuring compliance requires a carefully architected privacy strategy.
Cross-border data transfers must comply with legal frameworks that include adequacy decisions, Standard Contractual Clauses (SCCs), or Binding Corporate Rules (BCRs). Enrichment providers must ensure appropriate safeguards are in place and that data protection standards remain consistent regardless of where processing occurs.
Regional data residency requirements add another layer of complexity. Some jurisdictions require that citizens’ personal data remain within national borders, which can restrict where enriched data is stored or processed. Organizations must partner with platforms that support localized storage and processing options to meet these obligations.
Finally, sector-specific regulations may impose additional requirements depending on industry. Healthcare organizations must comply with HIPAA, financial institutions must adhere to GLBA and other financial privacy laws, and government contractors may face additional federal data-handling mandates. Each of these vertical-specific rules can shape enrichment strategies and influence platform selection.
Batch vs Real-Time Enrichment Strategies
Choosing between batch and real-time data enrichment isn’t just a technical decision—it’s a strategic one that shapes how quickly your organization can act on data-driven insights. Each model brings unique strengths and trade-offs in cost, performance, and responsiveness. In this section, we’ll break down the key differences, architectural requirements, and hybrid models that leading organizations use to balance speed, scalability, and cost efficiency in their enrichment workflows.
Understanding Processing Models
The choice between batch and real-time enrichment processing models is one of the most critical architectural decisions in implementing a successful data enrichment strategy. Each approach offers distinct advantages and limitations that must be aligned with specific use cases, data volumes, and technical capabilities.
Batch processing collects data over time and processes it in large groups at scheduled intervals. It’s ideal for scenarios where immediate enrichment isn’t required and cost efficiency is a key priority. Batch processing typically delivers lower per-record costs and handles very large volumes efficiently, making it suitable for back-office updates, periodic database refreshes, and historical enrichment tasks.
Real-time processing, in contrast, enriches data the moment it enters the system—enabling immediate action on fresh intelligence. It’s essential for time-sensitive applications such as form enrichment, instant lead qualification, and real-time personalization. The trade-off is higher cost and greater infrastructure complexity, as maintaining low latency and high availability requires reliable, scalable systems.
Near-real-time processing sits between the two models. It processes data in micro-batches within minutes of capture, striking a balance between responsiveness and cost control. For many organizations, this middle-ground approach offers the best mix of agility and efficiency for everyday business applications.
Batch Processing Implementation
Batch enrichment strategies demand careful orchestration of processing schedules, data volumes, and quality assurance procedures. The most effective implementations align processing efficiency with data freshness goals, ensuring cost and performance are optimized simultaneously.
Scheduling considerations must account for data source availability, system capacity, and business requirements. Many organizations schedule daily batch runs during off-peak hours to reduce system impact while ensuring enriched data is ready for next-day operations. For more dynamic use cases, enrichment frequency may increase to multiple times per day.
Volume management is crucial for performance optimization. Larger batches are typically more cost-efficient but can strain compute resources and extend processing times. Smaller batches refresh data more frequently but may reduce economies of scale. Finding the right balance requires continuous performance monitoring.
Error handling in batch processing must anticipate partial failures and provide mechanisms for automated reprocessing. Resilient systems use detailed logging, error categorization, and retry mechanisms for transient errors. Failed records are quarantined for manual review and correction to maintain data integrity.
Quality assurance is the final safeguard before enriched data enters production. Best practices include sampling enriched outputs, running automated validation checks, and performing manual verification on high-value records. These steps ensure confidence in the data while keeping turnaround times efficient.
Real-Time Processing Architecture
Real-time enrichment architectures require infrastructure capable of handling high-throughput, low-latency workloads while maintaining reliability and accuracy. These systems form the backbone of fast-moving marketing, sales, and analytics operations.
Modern stream processing frameworks such as Apache Kafka, Apache Pulsar, and cloud-native stream solutions enable high-performance pipelines for real-time enrichment. They support fault-tolerant, event-driven architectures capable of processing millions of records per minute with near-zero downtime.
Caching strategies are essential for minimizing latency and API usage. Multi-tier caching architectures—combining in-memory caches (like Redis or Memcached) for hot data with distributed caches for broader access—can significantly reduce response times. Cache invalidation policies must be carefully designed to maintain freshness and avoid stale data propagation.
Circuit breaker patterns play a critical role in ensuring system stability. They automatically detect service degradation or outages and redirect traffic away from failing endpoints while enabling graceful degradation of functionality. This prevents cascading failures and preserves overall platform performance.
Monitoring and alerting in real-time systems is non-negotiable. Key metrics such as latency, throughput, error rates, and data quality scores must be continuously tracked. Automated alerts enable teams to respond immediately to anomalies, ensuring consistent data flow and platform reliability.
Hybrid Processing Strategies
Most organizations find success with hybrid data enrichment architectures, combining batch and real-time processing to optimize for multiple business objectives. These systems deliver the responsiveness of real-time workflows for critical tasks and the cost efficiency of batch enrichment for bulk operations.
Use case segmentation is the first step. Identify which workflows demand real-time updates (e.g., lead scoring, personalization, fraud detection) versus those that can rely on scheduled batch enrichment (e.g., CRM cleansing, historical enrichment). This strategic alignment ensures resources are directed where speed matters most.
Data routing mechanisms handle the orchestration, directing records to the appropriate processing pipelines based on source type, record priority, and business context. Intelligent routing frameworks dynamically evaluate conditions and route accordingly, ensuring each record is enriched through the optimal path.
Consistency management guarantees that enriched data remains synchronized across all systems, regardless of processing mode. Techniques such as data versioning, conflict resolution rules, and synchronization workflows ensure that information processed in batch or real time reflects a unified, accurate view of the customer.
Data Hygiene Best Practices
Maintaining clean, accurate, and reliable data isn’t just good practice—it’s the backbone of every high-performing B2B data enrichment strategy. Strong data hygiene ensures that insights are trustworthy, systems run efficiently, and teams can make decisions with confidence. In this section, we’ll explore the foundational pillars of data governance, automated validation, and continuous improvement that keep enrichment programs scalable, compliant, and effective over time.
Establishing Data Governance
Effective data hygiene starts with a comprehensive governance framework that defines how data is collected, maintained, and managed throughout its lifecycle. A strong governance structure sets clear policies, processes, and ownership to uphold data quality across all systems and departments.
Data quality standards are at the heart of this framework. They establish measurable expectations for accuracy, completeness, consistency, and timeliness, aligned with specific business objectives. Different data types—such as contact records, company profiles, or behavioral data—may require distinct quality standards based on their purpose and impact within the organization.
Roles and responsibilities must be explicitly defined to ensure accountability. This typically includes:
- Data Stewards:Oversee specific data domains and ensure adherence to standards.
- Data Custodians: Manage the technical implementation of data policies and workflows.
- Data Owners: Make business-level decisions on how data is used and governed.
Data quality metrics provide the visibility needed for continuous improvement. Common KPIs include accuracy rates, completeness percentages, consistency scores, and timeliness benchmarks. These metrics should be regularly reviewed, reported to stakeholders, and used to drive targeted improvement initiatives across teams.
Automated Data Validation
Modern organizations rely on automated validation systems to maintain data quality at scale. These systems perform real-time checks and corrections as data moves through pipelines, ensuring that only clean, accurate, and standardized information enters operational environments.
Format validation confirms that data conforms to expected patterns and structures. This includes email syntax validation, phone number formatting, and data type checks. Simple but essential, format validation prevents a majority of common data entry and integration errors before they cascade downstream.
Business rule validation applies organization-specific logic to preserve consistency and contextual accuracy. Rules might include cross-field checks (e.g., ensuring job title matches department), range validation, or referential integrity constraints. These rules must evolve as business models, compliance requirements, and data use cases change.
Duplicate detection algorithms are crucial for eliminating redundant or conflicting records. Modern algorithms use fuzzy matching, phonetic similarity, and machine learning models to detect potential duplicates that exact matching would miss. Effective duplicate resolution workflows combine automation for scale with human review for precision.
Data enrichment validation ensures that external or appended data meets quality benchmarks before integration. It includes accuracy verification, completeness scoring, and consistency checks across systems. Failed validations should automatically trigger alerts, quarantines, or reprocessing steps to prevent low-quality enrichment from reaching production environments.
Continuous Monitoring and Improvement
Data hygiene is not a one-time project—it’s a continuous process that evolves with the organization’s data ecosystem. The most mature organizations establish comprehensive monitoring frameworks that track quality metrics in real time and identify emerging issues before they escalate.
Quality dashboards provide ongoing visibility into data health. These should be tailored to the audience:
- Executive dashboards highlight strategic trends and overall quality performance.
- Operational dashboards display granular metrics for daily management and troubleshooting.
Trend analysis goes a step further, revealing patterns and systemic issues over time. By correlating data quality trends with source reliability, system performance, or external variables, teams can uncover deeper causes and identify recurring weak points.
Root cause analysis helps pinpoint why data issues occur and how to prevent them from reappearing. This involves investigating both technical factors (like integration errors or API failures) and process factors (such as workflow gaps or inadequate training).
Improvement initiatives should be prioritized using an impact-versus-effort framework. Quick wins—high-impact, low-effort fixes—should be implemented first, followed by larger initiatives requiring deeper process or system redesign. Throughout, progress must be tracked and transparently communicated to stakeholders to reinforce accountability and sustained improvement.
Implementation Roadmap and Recommendations
A successful data enrichment initiative isn’t just about technology—it’s about strategy, alignment, and execution. Implementation requires a structured roadmap that connects technical capabilities to real business outcomes, while ensuring the organization is prepared to sustain long-term value. This section provides a step-by-step framework—from strategic planning through phased rollout—to help organizations build, scale, and measure a world-class enrichment program.
Strategic Planning Framework
A solid strategic planning framework lays the groundwork for successful enrichment implementation. It aligns business objectives, technical readiness, and change management into a cohesive plan designed to deliver measurable results and ongoing improvement.
Business case development is the first critical step. Organizations should quantify the expected benefits of data enrichment—including revenue uplift, cost reduction, and productivity gains—and define clear success metrics to track impact. Baseline measurements must be established early, ensuring ROI can be accurately evaluated over time.
Stakeholder alignment ensures all relevant teams share a unified vision of the initiative’s purpose, scope, and outcomes. Key stakeholders include executive sponsors, IT and data teams, sales and marketing leaders, and compliance officers. Regular communication cadences—through briefings, dashboards, or working sessions—keep everyone informed and engaged.
Technology assessment is where strategy meets execution. This phase involves evaluating current systems to identify integration points, infrastructure capacity, and potential constraints. Areas to assess include data architecture, API readiness, security protocols, and scalability requirements. A thorough assessment helps prevent technical bottlenecks during deployment and ensures smooth integration into the broader data ecosystem.
Phased Implementation Approach
A phased implementation strategy minimizes risk, accelerates learning, and builds organizational confidence as enrichment capabilities mature. Each phase should deliver tangible value while expanding technical and operational sophistication.
Phase 1: Foundation & Pilot
The initial phase focuses on establishing core capabilities. This includes vendor selection, integration of foundational APIs, data mapping, and pilot use cases. The goal is to demonstrate quick wins—validating the business case while setting up scalable infrastructure and governance frameworks.
Phase 2: Expansion & Scalability
Once foundational elements are proven, enrichment can be extended to additional use cases, departments, and data sources. This phase typically introduces real-time enrichment, more advanced automation, and analytics-driven insights. The objective is to scale what works while maintaining data quality and performance consistency.
Phase 3: Optimization & Innovation
The final phase focuses on continuous optimization. Organizations integrate predictive analytics, AI-powered insights, and end-to-end automation to maximize ROI. Feedback loops, performance benchmarking, and process refinement ensure the enrichment system evolves in tandem with business needs and market changes.
Each phase should conclude with structured evaluations, ensuring data accuracy, user satisfaction, and business impact are tracked before moving forward.
Success Metrics and KPIs
Defining and tracking the right success metrics ensures that data enrichment initiatives deliver measurable outcomes and stay aligned with business goals. These KPIs serve as the foundation for accountability, optimization, and long-term value creation.
Data quality metrics measure the precision and reliability of enriched data. Common KPIs include accuracy, completeness, consistency, and timeliness. Tracking these metrics highlights the effectiveness of enrichment workflows and pinpoints areas for improvement.
Business impact metrics connect enrichment directly to performance outcomes such as conversion rate increases, pipeline velocity, sales productivity, and marketing efficiency. Demonstrating quantifiable business impact reinforces executive confidence and secures continued investment.
Operational efficiency metrics evaluate the performance of enrichment systems themselves—monitoring processing times, error rates, data freshness intervals, and system uptime. These KPIs ensure enrichment workflows are both efficient and resilient.
User adoption metrics reflect the human side of success. High adoption rates indicate effective training, change management, and perceived value among end users. Conversely, low adoption signals areas where workflow alignment or additional enablement may be needed to ensure sustained engagement.
How Delverise Can Help
Choosing the right tools and strategy is only the first step — executing effectively is what separates high-growth teams from the rest. At Delverise, we help B2B SaaS companies build and optimize their revenue engines, from tool selection and implementation to full GTM execution.
Whether you’re evaluating b2b data enrichment tools, building your sales tech stack, or scaling your go-to-market operations, our team combines RevOps strategy with hands-on engineering to deliver measurable results.
Ready to build a revenue engine that actually scales? Reach out to Delverise about your GTM strategy.
Make the Next 30 Days Count
If you want a fast, low-risk way to turn this framework into results, request a short working session to pressure-test tool fit by ICP/region, pick the right batch vs. real-time cut, and set the quality gates that protect ROI.
Related Articles
- Best Sales Intelligence Tools
- Clearbit vs ZoomInfo
- Clay vs Apollo for Sales Teams
- Outbound Sales for B2B SaaS
- What Is a Customer Data Platform?